|
To monitor our infrastructure we choose one of the most popular monitoring software, ELK Stack: Elasticsearch, Logstash and Kibana. 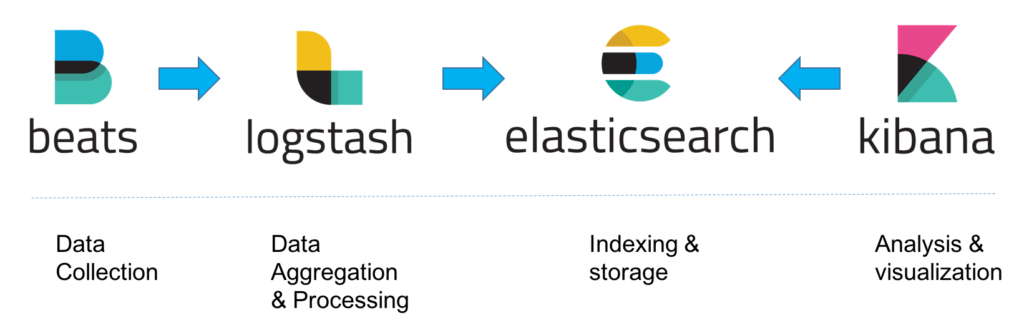 At Nirva Software our cloud instances are managed with Docker swarm or Virtual machines on Proxmox. When you manage dozens of machines you need a to have one entry-point to monitor all the infrastructure. Monitoring an infrastructure is not magic, you need probes and data. With our current infrastructure we gather:
Our monitoring team use all these metrics to build counters, alerts and visualization graphs. See some practical examples below. Apache monitoring Using the apache logs you can extract an approximate origin of the people connecting (or trying to connect) to your solution. If your apache server handles 80% of its traffic with connections coming from countries where you don't have clients, a simple fail2ban solution will probably be interesting to block this traffic. The apache server may act as a proxy, so a DDOS attack will also trigger alert if you monitoring your sever wisely. 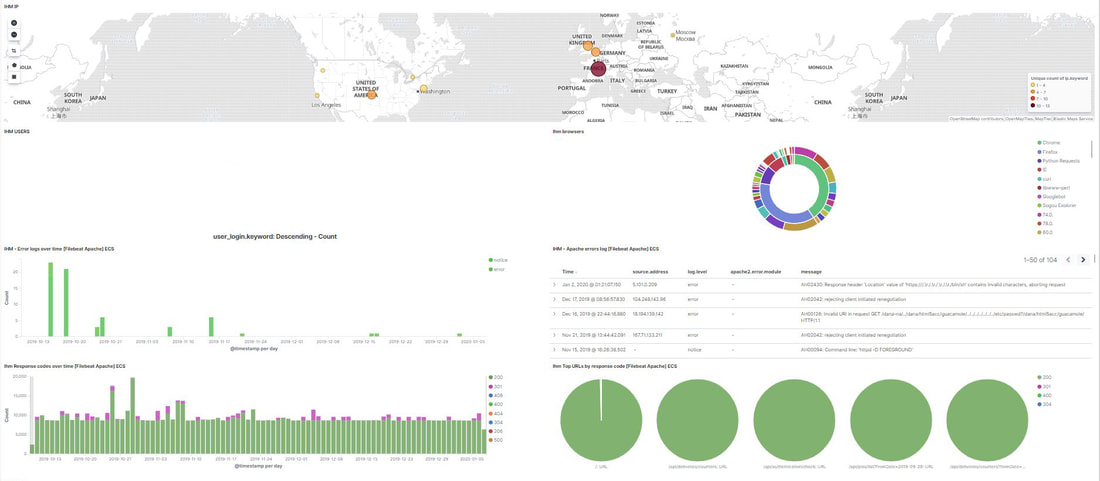 e.g.: a test environment accessed mainly from France, United Kingdom and United States. Everything fine. Host monitoring Hard disk monitoring and memoy consumption are two important metrics for the hosts. Do we need to add more hard disk, do we need more memory ? 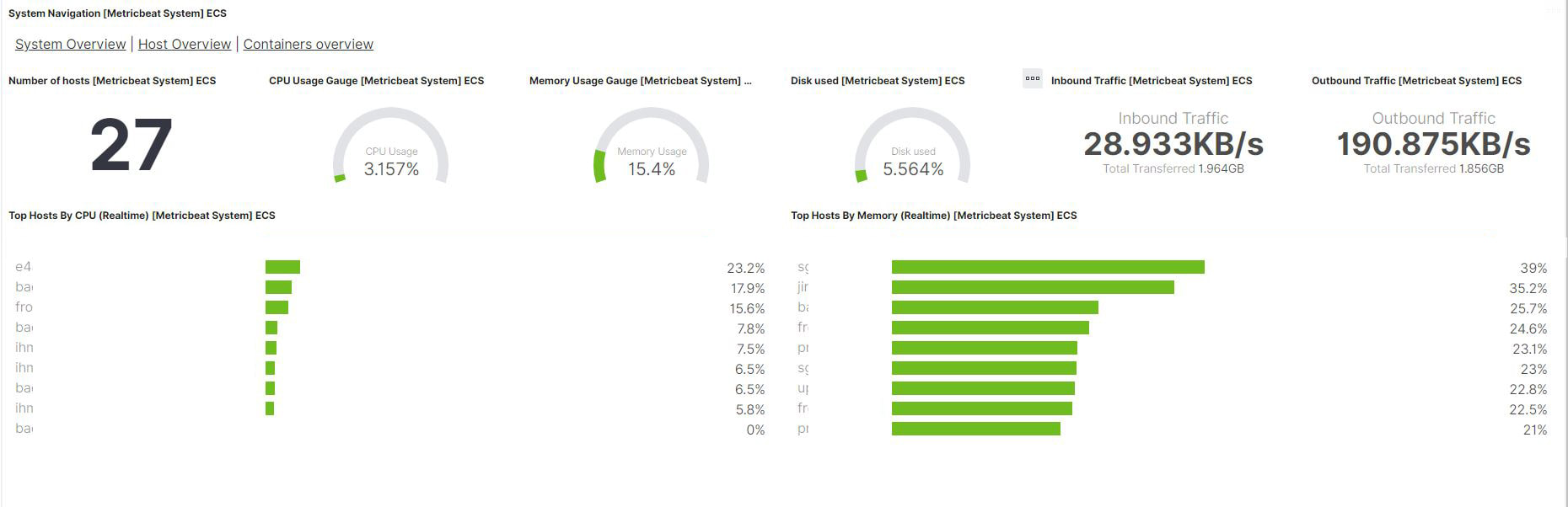 At a glance we identify which machine is becoming the bottleneck in the system and we can act quickly by adding new host in the network. Conclusion
Monitoring is very important when setting up a service. You may have the best software, but if you are not able to monitor it properly, then you will finnaly crash your system. At NIRVA we have dedicated a team to control all our internal and cloud infrastructures. Every month plans are made to adapt the current monitoring solution. This is why we decided to focus on setting up dedicated cloud environments for our customers. We take care of the infrastructure by managing the servers, and you take care of developing your business using your dedicated Intelligent Hybrid Mail instance. |

|
|
|

|